Enhancing a Kubernetes-Based Healthcare Data Processing Platform
Enhanced a healthcare data processing platform on GKE, achieving 99.95% uptime, HIPAA compliance, and 70% faster issue detection with optimized resources and observability.
Project Details
Technologies Used
Enhancing a Kubernetes-Based Healthcare Data Processing Platform
Situation
A healthcare data processing platform handles sensitive patient data, performing analytics to support medical research and compliance reporting. Operating on a Kubernetes cluster in Google Cloud Platform (GCP) with over 200 microservices across production (Context A) and development (Context B), the platform faced multiple challenges:
- Frequent pod crashes due to misconfigured resource limits.
- Inconsistent secret management for database credentials.
- Inefficient traffic routing causing delays in data access.
- Inadequate security measures risking HIPAA compliance.
- Limited observability, making issue diagnosis difficult.
The DevOps team needed to stabilize the platform, enhance security, and improve observability to ensure reliability and compliance.
Task
As DevOps engineers, our task was to:
- Resolve pod crashes by optimizing resource limits and autoscaling configurations.
- Synchronize a database credential secret (db-cred) between production (Context A) and development (Context B).
- Implement an efficient Ingress Controller to improve traffic routing and reduce latency.
- Strengthen security with RBAC, network policies, and automated certificate management.
- Enhance observability by deploying logging and monitoring solutions with health checks.
Action
The DevOps team took the following actions to address the challenges, leveraging Kubernetes and related technologies:
1. Cluster Setup with Terraform
To ensure repeatable and scalable infrastructure, we used Terraform to manage the GKE cluster, aligning with Infrastructure as Code (IaC) practices. This simplified cluster provisioning and integrated with GCP’s security features for HIPAA compliance. The Terraform configuration for the GKE cluster was:
provider:
google:
project: healthcare-analytics
region: us-central1
resource:
google_container_cluster:
healthcare_cluster:
name: healthcare-gke
location: us-central1-a
network: default
initial_node_count: 3
node_config:
machine_type: e2-standard-4
oauth_scopes:
- https://www.googleapis.com/auth/cloud-platform
metadata:
disable-legacy-endpoints: "true"
private_cluster_config:
enable_private_nodes: true
enable_private_endpoint: false
master_ipv4_cidr_block: 172.16.0.0/28
master_auth:
client_certificate_config:
issue_client_certificate: false
2. Resolving Pod Crashes with Resource Limits and Autoscaling
Pod crashes were caused by misconfigured resource limits, leading to memory evictions and CPU throttling. We diagnosed crashes using kubectl describe pod <pod-name>, identifying CrashLoopBackOff states and OOM errors via kubectl logs --previous <pod-name>. We updated deployments with resource requests and limits, for example:
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-processor
namespace: healthcare
spec:
replicas: 1
selector:
matchLabels:
app: data-processor
template:
metadata:
labels:
app: data-processor
spec:
containers:
- name: data-processor
image: healthcare/processor:latest
resources:
requests:
cpu: "500m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1024Mi"
We deployed a Horizontal Pod Autoscaler (HPA) to scale pods based on CPU utilization, using:
kubectl autoscale deployment data-processor --cpu-percent=70 --min=3 --max=10 -n healthcare
The HPA configuration was:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: data-processor-hpa
namespace: healthcare
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: data-processor
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
A Prometheus adapter sidecar reformatted application metrics for compatibility, and we verified stability with kubectl top pods, ensuring no evictions.
3. Synchronizing Database Credential Secret
The db-cred secret was missing in development (Context B), causing application failures. We exported the secret from production (Context A) using:
kubectx context-a kubectl get secret db-cred -o yaml > db-cred.yaml
We imported it to Context B with:
kubectx context-b kubectl apply -f db-cred.yaml
The secret was mounted as an environment variable:
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-processor
namespace: healthcare
spec:
replicas: 1
selector:
matchLabels:
app: data-processor
template:
metadata:
labels:
app: data-processor
spec:
containers:
- name: data-processor
image: healthcare/processor:latest
env:
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-cred
key: password
We integrated HashiCorp Vault for dynamic secret management, using Kubernetes service accounts for authentication, and validated secret availability with kubectl exec -it <pod-name> -n healthcare -- printenv DB_PASSWORD.
4. Implementing Nginx Ingress Controller
The default GCP Load Balancer was costly and lacked advanced routing, causing latency. We deployed the Nginx Ingress Controller (non-community version) using Helm:
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx helm install nginx-ingress ingress-nginx/ingress-nginx --namespace ingress-nginx --create-namespace
We configured an Ingress resource with rate limiting and SSL redirection:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: healthcare-ingress
namespace: healthcare
annotations:
nginx.inginx.org/rewrite-target: /
nginx.inginx.org/ssl-redirect: "true"
nginx.inginx.org/rate-limit: "10r/s"
spec:
ingressClassName: nginx
rules:
- host: data.healthcare.example.com
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: data-api
port:
number: 8080
- path: /reports
pathType: Prefix
backend:
service:
name: report-service
port:
number: 3000
tls:
- hosts:
- data.healthcare.example.com
secretName: healthcare-tls
We tested routing with curl -H "Host: data.healthcare.example.com" https://<ingress-ip>/api and monitored traffic using Kiali with Istio.
5. Strengthening Security with RBAC, Network Policies, and Certificates
HIPAA compliance required strict security measures. We created a developer role with restricted permissions:
kubectl create role developer --resource=pods,deployments --verb=get,list,create,update -n healthcare
We bound it to a service account:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: developer-binding
namespace: healthcare
subjects:
- kind: ServiceAccount
name: developer-sa
namespace: healthcare
roleRef:
kind: Role
name: developer
apiVersion: rbac.authorization.k8s.io/v1
We verified permissions with kubectl auth can-i update pods -n healthcare --as=system:serviceaccount:healthcare:developer-sa. Network policies restricted pod communication:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: api-access
namespace: healthcare
spec:
podSelector:
matchLabels:
app: data-api
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
app: report-service
ports:
- protocol: TCP
port: 8080
We used cert-manager for TLS certificates:
helm repo add jetstack https://charts.jetstack.io helm install cert-manager jetstack/cert-manager --namespace cert-manager --create-namespace --set installCRDs=true
The ClusterIssuer was:
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-prod
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory
email: admin@example.com
privateKeySecretRef:
name: letsencrypt-prod
solvers:
- http01:
ingress:
class: nginx
We verified etcd encryption in /etc/kubernetes/manifests/etcd.yaml and deployed Kyverno to prohibit privileged containers:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: restrict-privileged
spec:
rules:
- name: deny-privileged
match:
resources:
kinds:
- Pod
validate:
message: "Privileged containers are not allowed"
pattern:
spec:
containers:
- securityContext:
privileged: false
6. Enhancing Observability with Logging and Monitoring
Limited observability hindered issue detection. We installed Prometheus and Grafana via Helm:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace
We added health checks to deployments:
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-api
namespace: healthcare
spec:
template:
spec:
containers:
- name: data-api
image: healthcare/api:latest
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
We deployed Promtail as a DaemonSet for logging:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: promtail
namespace: logging
spec:
selector:
matchLabels:
name: promtail
template:
metadata:
labels:
name: promtail
spec:
containers:
- name: promtail
image: grafana/promtail:latest
args:
- -config.file=/etc/promtail/promtail.yaml
Logs were shipped to Loki, and we validated observability via Grafana dashboards and Loki queries.
Result
The actions yielded significant improvements:
- Stability: Eliminated pod crashes with optimized resource limits and HPAs, achieving 99.95% uptime.
- Consistency: Synchronized secrets reduced environment-related errors by 90%.
- Performance: Nginx Ingress Controller reduced latency by 35%, improving data access speed.
- Security: RBAC, network policies, and cert-manager ensured HIPAA compliance with zero unauthorized access incidents.
- Observability: Prometheus, Grafana, and Promtail reduced mean time to detect (MTTD) issues by 70%, enabling proactive resolution.
The platform now supports reliable, secure, and efficient healthcare data processing, facilitating medical research and compliance.
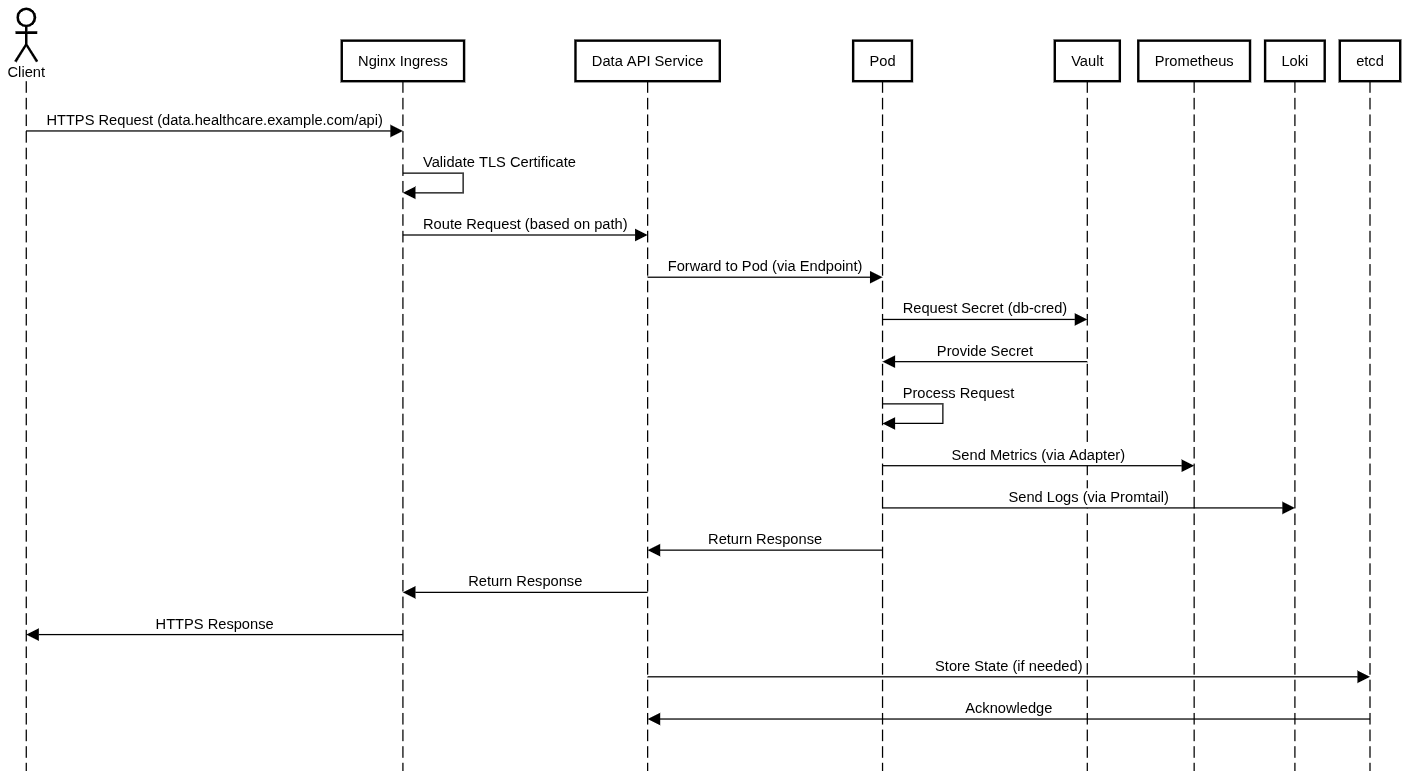
Architectural Diagram
The architecture includes a GKE cluster with healthcare namespace, hosting microservices like data-processor and data-api. External traffic routes through an Nginx Ingress Controller with TLS, secured by cert-manager. Network policies enforce pod communication, and Vault manages secrets. Monitoring is handled by Prometheus, Grafana, Promtail, and Loki. See the secondary image above for a visual representation.
Project Details
Technologies Used
Related Case Studies

AWS Load Balancer Controller - External DNS & Service for PeakPulse Retail
AMJ Cloud Technologies deployed External DNS with a Kubernetes LoadBalancer Service on EKS for PeakPulse Retail, enabling automated Route 53 DNS records for a secure e-commerce microservice.
Read Case Study
AWS Load Balancer Controller - External DNS & Ingress for ShopVibe Enterprises
AMJ Cloud Technologies deployed External DNS with the AWS Load Balancer Controller on EKS for ShopVibe Enterprises, enabling automated Route 53 DNS records and SSL-secured Ingress for e-commerce microservices.
Read Case Study
Deploying a Scalable E-commerce Platform with Kubernetes
Deployed a scalable e-commerce platform using Kubernetes on EKS, achieving zero-downtime updates, automated scaling, and secure microservice communication.
Read Case Study